Building tenets: Intelligent Context Aggregation for AI Pair Programming
Uncanny AI coding assistants
I've used all the AI pair programming tools - CoPilot Chat, Cursor, Codex, Claude Code, aider, Windsurf (not so much anymore). They all have access to your Git repos and basic terminal commands (if you give it to them, though from anecdotes on the web and my personal experiences as well, it's clear that permissions isn't really a deterministic thing in these tools though that's a different discussion), like ls and grep, and of course nano or rm.
A strange thing with LLMs, when working with Copilot Chat at least, is you will tell them something specific: "logic in the summarizer is looping twice because the batch processor isn't clearing the processed_chunks var, fix it", which is not a great prompt but gets things started, and then you'll see the tool calling commands running:
# First attempt - literal string matching
grep -r "batch processor isn't clearing the processed_chunks"
grep -r "looping twice"
then maybe:
# Second attempt - basic word stemming
grep -r "summar\(y\|izer\|ies\|ize\|ization\)"
grep -r "loop\(ing\|ed\|s\)\?\s*twice\|double\|duplicate"
and maybe then:
# Third attempt - finally looking for actual variable names
grep -r "processed_chunks\|process_chunks\|chunk_process\|chunks_processed"
grep -r "self\.processed_chunks"
It usually finds a good match 1-2 attempts after the first failed honestly, it's not such a hindrance you find it to be a real issue.
The example's exaggerated to demonstrate a symptom of something larger at play, cause I guess what really gets me is the first step always (at the moment) seems to be, query the exact phrase the user's looking for in every file. That is dumb, even for a first move, even for a LLM. (Of course, this is subject to change, but as of the time of this writing, that's the common behavior of Copilot Chat).
What's also strange is LLMs won't (probably discouraged from ingesting too many tokens) try too hard in navigating your directory structure to fully understand your code. Claude Opus (as of the date of this post) will literally just try to read the first 100 lines of any relevant file or so before it stops (by default), assuming it's gotten enough information from that to move forward.
And we're not even going to think about the costs of additional LLM calls when static tools could do the job, especially when conversations get larger and LLMs start summarizing with more LLMs.
What is
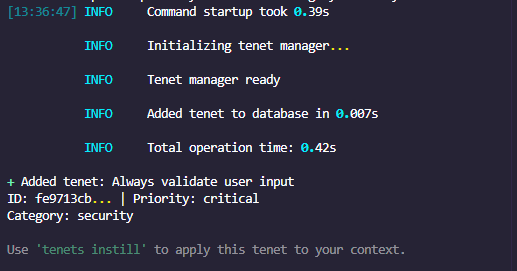
tenets is a Python library and CLI tool that intelligently navigates repos (or any directory of files) to match, analyze, summarize, and aggregate the most relevant context (set of documents) for a query. It's currently tuned to work with coding with AI assistants, but the core functionality can be applied for any document matching service, including search engines.
It uses deterministic algorithms (regex, BM25) with optional deep learning embeddings for semantic understanding, and extractive summarization and factors high-level metadata (how many times a function is referenced, how complex a function may be, imports / dependencies) and other metrics for heuristics in its rankings.
Beyond basic BM25, tenets implements:
- Code-aware tokenization that splits
camelCaseandsnake_casewhile preserving originals for exact matching - Multi-signal ranking combining 10+ orthogonal factors (import centrality, git signals, AST complexity)
- Dynamic programming for file packing to optimize which files to include in full vs summarized within token budgets
- Task-specific weight adjustments - different factors for
debugvsrefactorvsfeaturetasks - File structure aware summarization that preserves signatures, docstrings, and complex functions over simple ones
None of tenets's functionality costs API credits - all processing is done locally. There are optional LLM integrations for summarizing, but the recommended route is using the built-in summarizer algorithms first.
tenets is able to perform its full distillation functionality on complex repos with hundreds of source files typically in 30-40 seconds, making it usable as a programmatic API (in fast mode) for pair programming tools like aider or Claude CLI.
And yes at some late midway point in tenet's development, I dogfooded the tool to help it build itself. Tenets was built with the help of Copilot Chat (GPT-5) and Claude Opus / Sonnet.
Features in Action
Context Building
When you run tenets distill "add mistral api to summarizer", tenets analyzes your codebase.
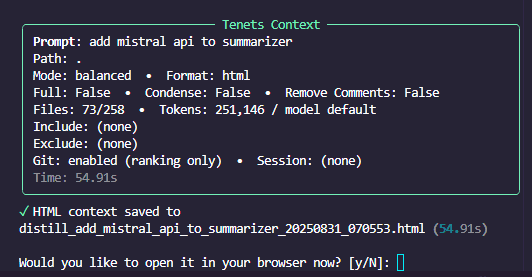
Link GitHub issue or Jira issues in a query and tenets will fetch and extract those contents automatically.
File Ranking
tenets rank "fix summarizing truncation bug" --tree
![]()
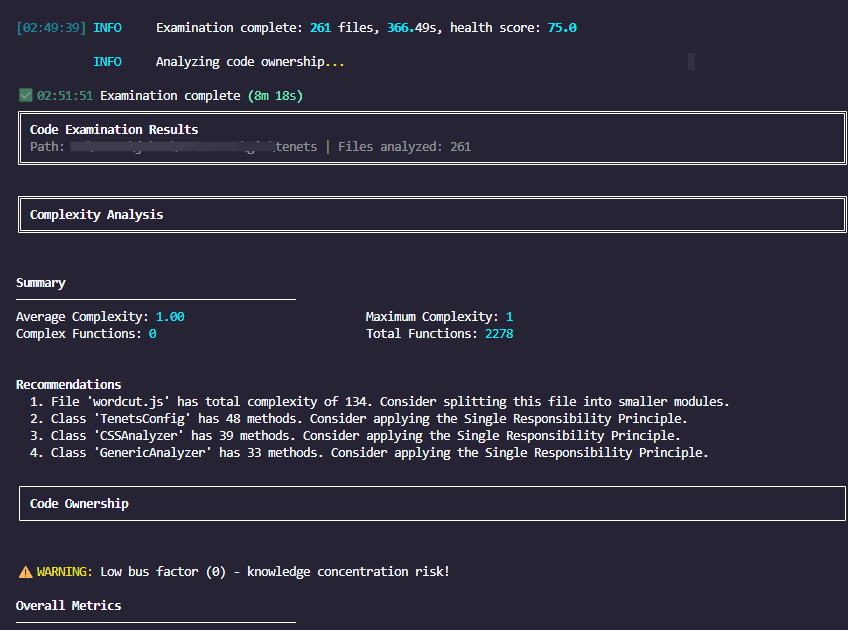
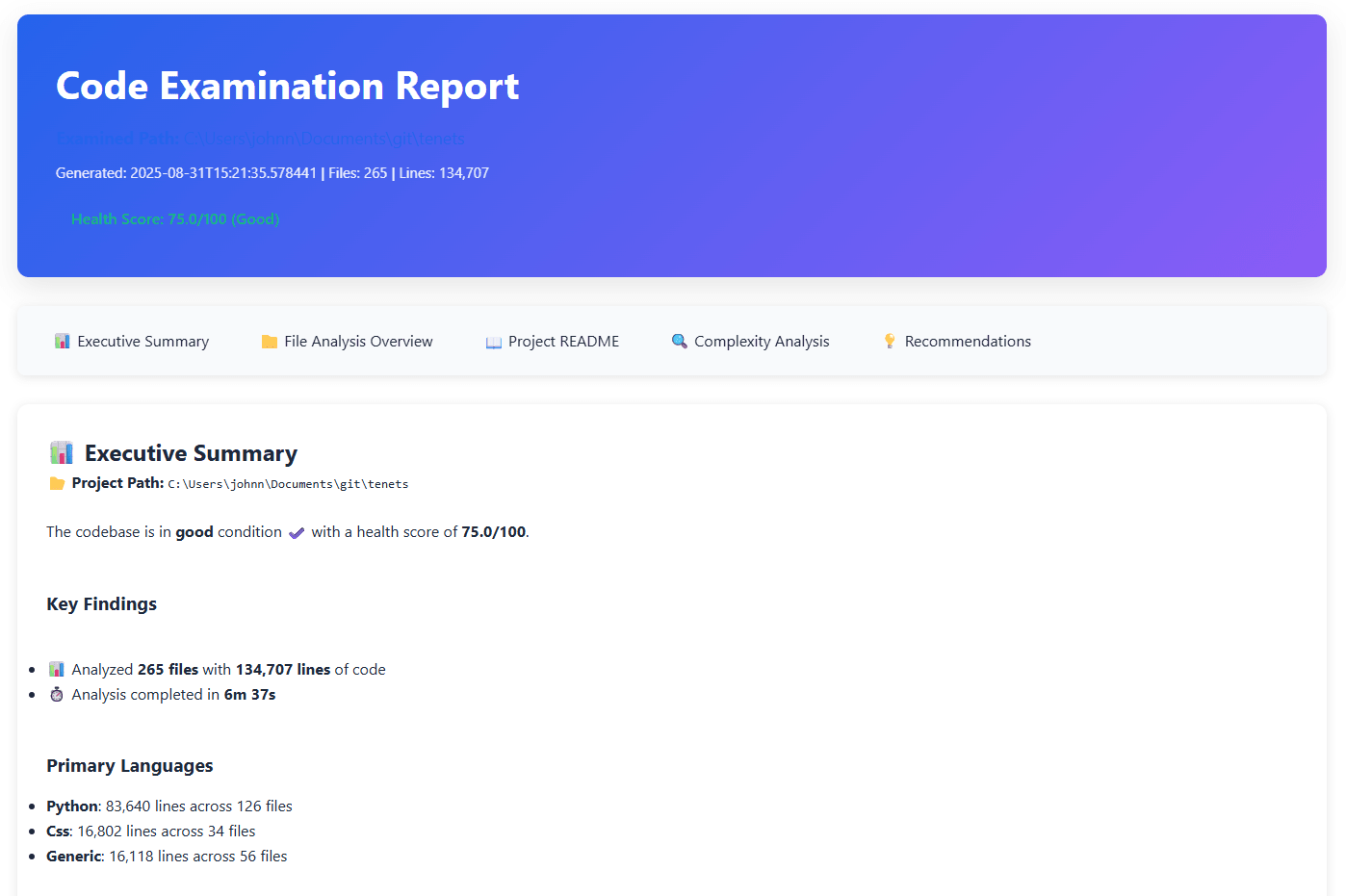
Code Analysis & Quality Metrics
tenets examine . --complexity --hotspots --ownership
Session Management
Sessions maintain context across multiple interactions.

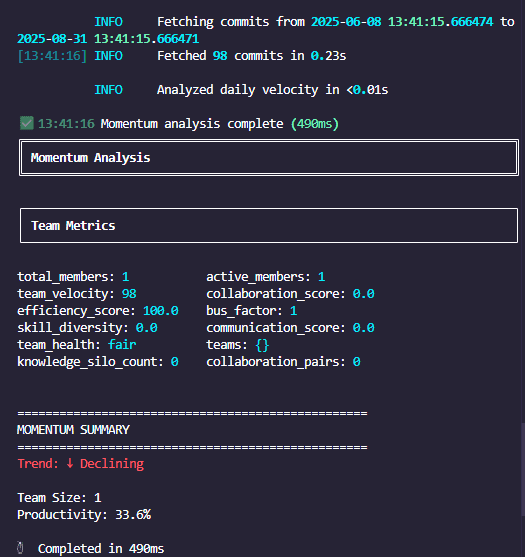
Team Velocity & Visualization

Technical Design
Tenets operates in 3 modes, fast, balanced, and thorough. Balanced is about 1.5x slower than fast, and thorough is about 4x slower. Thorough utilizes ML (deep learning) embeddings (sentence transformers bi-encoders and cross-encoders) for semantic searching and matching.
Ranking / similarity
BM25 is a probabilistic ranking algorithm that scores documents for relevancy, with term saturation so there's diminishing returns for repeated terms, and document length normalization, making BM25 superior over tf-idf in this case, and in many general cases (but not always). Since code files vary from 10 to 10,000+ lines, length shouldn't bias relevance too much.
Code is inherently redundant. A test file with 50 instances of assert response.status == 200 shouldn't dominate searches for "response", of course.
We also support TF-IDF with sparse cosine similarity (can be but is not usually faster with pre-compute, uses more memory), but BM25 is recommended.
We purposefully exclude stemming / lemmatization, the process of normalizing text so all word forms become base words only, because the difference between summary() method and Summary(), or summarize versus summarized matters greatly in code, not so much in something like journalism and news for example (which tenets would have to be reconfigured to support better).
Sentence transformers in optional ML embeddings path would be the best way, given it can differentiate these aspects while also still understanding they match closely in vector space. Exact matches (capitalization) impact rankings as well, but aren't required for a match.
All that in mind, the tip when using tenets is to be clear with your variable names, capitalization for variables / classes / methods, and make absolutely zero typos (unlike interacting with LLMs).
Code-Aware Tokenization
Tenets has custom code-aware tokenizing. A standard NLP tokenizer would not maintain code understanding. They'd see getUserAuthToken as one meaningless blob, missing that it's really get, user, auth, and token.
# The problem we're solving
text = "class UserAuthHandler implements getUserAuthToken"
# Standard tokenizer output:
["class", "userauthhandler", "implements", "getuserauthtoken"]
# Searching for "auth" finds nothing!
# Our tokenizer output:
["class", "user", "auth", "handler", "userauthhandler", # both parts AND whole
"implements", "get", "user", "auth", "token", "getuserauthtoken"]
# Now "auth" matches, but exact match "auth" variables score higher
Here's a simplified version of how tenets handles this in practice:
def tokenize_code(text: str) -> List[str]:
tokens = []
# Extract all identifiers
for match in re.findall(r'\b[a-zA-Z_][a-zA-Z0-9_]*\b', text):
# Handle camelCase/PascalCase
if any(c.isupper() for c in match) and not match.isupper():
parts = re.findall(r'[A-Z][a-z]+|[a-z]+|[A-Z]+(?=[A-Z][a-z]|\b)', match)
tokens.extend([p.lower() for p in parts])
tokens.append(match.lower()) # Keep original for exact matching
# Handle snake_case
elif '_' in match:
parts = match.split('_')
tokens.extend([p.lower() for p in parts if p])
tokens.append(match.lower()) # Original preserved
else:
tokens.append(match.lower())
return list(dict.fromkeys(tokens)) # Dedupe while preserving order
This means searching for "auth" finds authenticate(), user_auth, AuthHandler, and getUserAuth() - but each scores differently based on exact vs partial matches.
Optimal File Packing
Say you have 8K tokens. Three files: A (highly relevant, 6K tokens), B (very relevant, 3K tokens), C (very relevant, 3K tokens).
Given a token budget, which files should be included full vs summarized? This is the knapsack problem with a twist - files can be "packed" in two sizes. We use dynamic programming to maximize total relevance score within the token constraint and still be algorithmically viable. Each file can be included in full (100% tokens, 100% relevance), summarized (~25% tokens, ~60% relevance), or skipped.
The algorithm builds a table where dp[i][j] = "maximum relevance using first i files with j tokens". For each file, it picks the best option: skip it, include it full, or include a summary.
Here's a demo of the actual implementation:
def optimize_packing(files: List[FileAnalysis], max_tokens: int) -> List[Tuple[File, bool]]:
n = len(files)
# dp[i][j] = max relevance using first i files with j tokens
dp = [[0.0] * (max_tokens + 1) for _ in range(n + 1)]
for i in range(1, n + 1):
file = files[i-1]
full_tokens = count_tokens(file.content)
summary_tokens = full_tokens // 4 # Rough estimate
for j in range(max_tokens + 1):
# Option 1: Skip file
dp[i][j] = dp[i-1][j]
# Option 2: Include full
if j >= full_tokens:
score = dp[i-1][j-full_tokens] + file.relevance_score
dp[i][j] = max(dp[i][j], score)
# Option 3: Include summary (degraded value)
if j >= summary_tokens:
score = dp[i-1][j-summary_tokens] + file.relevance_score * 0.6
dp[i][j] = max(dp[i][j], score)
# Backtrack to find selection
return backtrack_solution(dp, files, max_tokens)
Multi-Signal Ranking
tenets combines 10 different factors with configurable weights:
keyword_match: 0.20 # Direct keyword presence
bm25_score: 0.25 # BM25 relevance (primary)
path_relevance: 0.15 # Path/filename matching
import_centrality: 0.10 # How often file is imported
git_recency: 0.05 # Recent changes
git_frequency: 0.05 # Change frequency
semantic_similarity: 0.10 # Embedding similarity (if ML)
code_patterns: 0.05 # Domain patterns
complexity_relevance: 0.03 # Cyclomatic complexity
ast_relevance: 0.02 # AST structure matching
Import centrality is a metric to identify which files are most important to a codebase. We count how many files import each file (incoming) and how many it imports (outgoing), with incoming weighted higher as imported signals importance.
Based on the task intent, weights adjust:
if intent == "debug":
weights["git_recency"] *= 2.0 # Recent changes matter
weights["code_patterns"] *= 1.5 # Error handling patterns
elif intent == "refactor":
weights["complexity_relevance"] *= 2.0 # Complex code needs refactoring
weights["import_centrality"] *= 1.5 # Core abstractions
..
Parallel Processing & Caching
We use parallelization in multiple stages. Building indices is sequential but ranking factors calculate in parallel across available cores.
We stream results as they become available instead of waiting for everything to complete. Cache is multi-tier: memory for hot data which is very fast, SQLite for warm which is fast, disk for cold which is slower.
Architecture challenge: A functional CLI + Python API
Building a code intelligence platform needs to be responsive and fast, even as it loads necessary ML dependencies or performs recursive folder searching.
With tenets, naturally we'd want to build a nice CLI and Python API in parallel (one of tenet's major use cases is potential integration into AI tools in IDEs, etc).
# Initial this is our build - looks clean, but circular import hell
from tenets import Tenets
@app.command()
def distill(prompt: str):
tenets = Tenets() # Imports everything
return tenets.distill(prompt)
Python 3.7+ enables proper lazy loading without breaking conventions:
# tenets/__init__.py
_LAZY_IMPORTS = {
'Distiller': 'tenets.core.distiller.Distiller',
'Instiller': 'tenets.core.instiller.Instiller',
'CodeAnalyzer': 'tenets.core.analysis.analyzer.CodeAnalyzer',
}
def __getattr__(name):
"""Lazy import heavy components on first access."""
if name in _LAZY_IMPORTS:
import importlib
module_path, attr_name = _LAZY_IMPORTS[name].rsplit('.', 1)
module = importlib.import_module(module_path)
attr = getattr(module, attr_name)
globals()[name] = attr # Cache for future
return attr
raise AttributeError(f"module {__name__!r} has no attribute {name!r}")
# Usage remains clean:
from tenets import Distiller # No import yet
d = Distiller() # NOW it imports
The CLI only imports what each command needs:
# app.py - Conditional command loading
import sys as _sys
if len(_sys.argv) > 1 and _sys.argv[1] in ["distill", "instill"]:
from tenets.cli.commands.distill import distill
app.command()(distill)
else:
# Lightweight placeholder for help text
@app.command(name="distill")
def distill_placeholder(ctx: typer.Context, prompt: str):
"""Distill relevant context from codebase."""
from tenets.cli.commands.distill import distill
return ctx.invoke(distill, prompt=prompt)
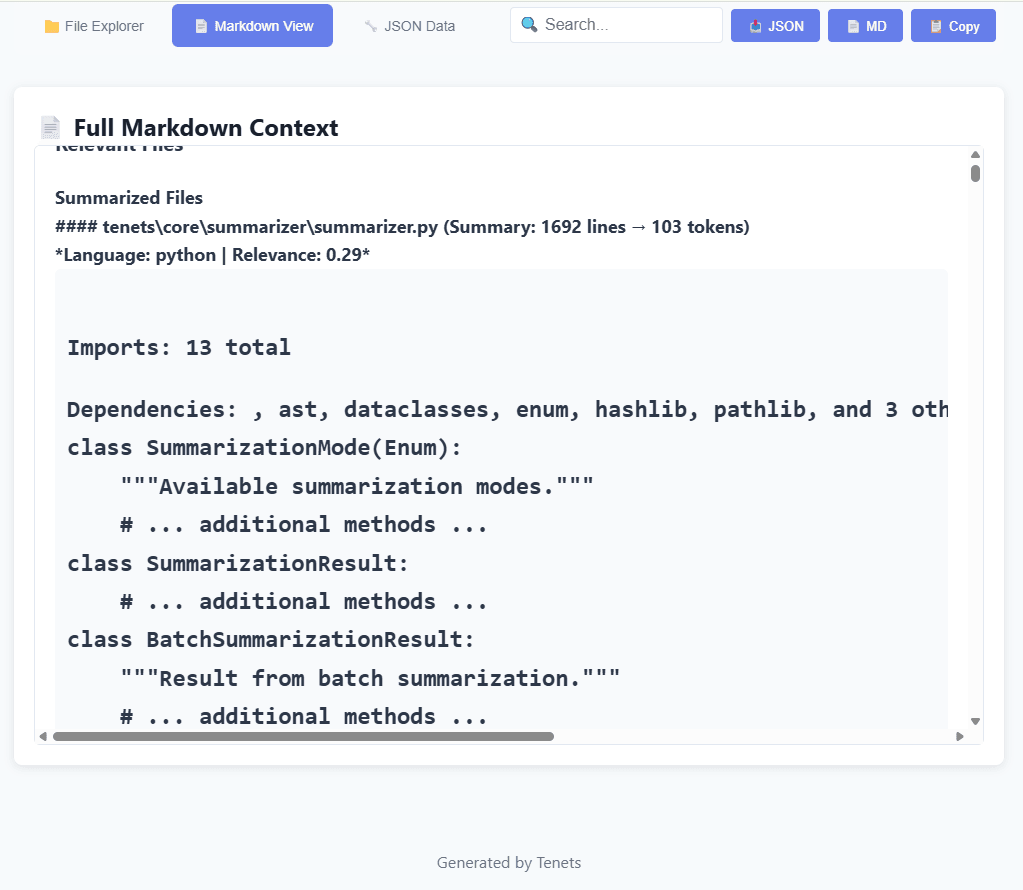
Smart Summarization
Rather than naive line truncation, our summaries are AST-aware. We keep function signatures, complex functions (cyclomatic > 10), frequently-called functions, and drop simple getters/setters and duplicate test cases first.
Large files with dozens of imports waste tokens. We intelligently condense:
# Instead of 20+ lines of imports
# We generate:
# Imports: 27 total
# Dependencies: os, sys, json, yaml, pathlib, typing, collections
# Local imports: 3
Session Management
Sessions maintain context across multiple interactions, with pinned files guaranteed inclusion. Here's the core concept i9n code:
class SessionContext:
def __init__(self, session_name: str):
self.name = session_name
self.pinned_files: List[Path] = []
self.tenets: List[Tenet] = []
self.history: List[DistillResult] = []
def distill_with_context(self, prompt: str, max_tokens: int):
# Pinned files get first priority
token_budget = max_tokens
included = []
# Include pinned files first (with safety check)
for pinned in self.pinned_files:
file_tokens = count_tokens(pinned.read_text())
if file_tokens < token_budget * 0.5: # No single file > 50% budget
included.append(pinned)
token_budget -= file_tokens
# Then rank and add other files
remaining_files = rank_files(prompt, exclude=self.pinned_files)
for file in remaining_files:
if can_fit(file, token_budget):
included.append(file)
token_budget -= file.tokens
Git Signals and Test Detection
Recent changes matter more for debugging, but frequency matters for understanding core files. This is how tenets calculates git signals:
def calculate_git_signals(file_path: str, commits: List[Commit]) -> Dict[str, float]:
# Recency: exponential decay with 30-day half-life
if last_modified := get_last_modified(file_path, commits):
days_ago = (datetime.now() - last_modified).days
recency = math.exp(-days_ago / 30) # e^(-t/τ)
else:
recency = 0.0
# Frequency: logarithmic scaling to prevent outliers
commit_count = count_commits_touching_file(file_path, commits)
if commit_count <= 5:
frequency = 0.3
elif commit_count <= 20:
frequency = 0.6
else:
# Log scale for very active files
frequency = min(1.0, 0.8 + math.log(commit_count / 20) / 10)
return {
'recency': recency,
'frequency': frequency,
'combined': recency * 0.4 + frequency * 0.4
}
ML embeddings / semantic similarity
We use sentence-transformers with all-MiniLM-L6-v2 by default. Dense embeddings convert code into numerical vectors where similar code ends up nearby in vector space.
The model was trained on millions of code/text pairs to learn that authenticate(), login(), and verify_user() should cluster near each other in high-dimensional space, even though they share zero characters. When you search for "user auth" with ML enabled, your query finds files with embeddings that have high cosine similarity.
The problem with standard embedding search (bi-encoders) is they encode query and document separately, and then compare. They have no understanding of context between them. The query "implement OAuth2" and document "DEPRECATED: OAuth2 removed in v3.0" will score high because both encode OAuth2 strongly, when the two have opposite intentions.
Cross-Encoder Architecture
Cross-encoders solve this by processing query and document together through transformer self-attention:
# Bi-encoder (standard embeddings) - processes separately
query_embedding = model.encode("implement OAuth2") # [0.23, -0.45, ...]
doc_embedding = model.encode("OAuth2 is deprecated") # [0.21, -0.43, ...]
similarity = cosine_similarity(query_embedding, doc_embedding) # High! 0.95
# Cross-encoder - processes together
combined_input = f"Query: implement OAuth2 [SEP] Document: OAuth2 is deprecated"
relevance = cross_encoder.predict(combined_input) # Low! 0.15
Through self-attention layers, "implement" attends to "deprecated" and realizes they're opposites. The model outputs a single relevance score, not embeddings.
The tradeoff is speed. Bi-encoders compute embeddings once and reuse them - O(n) for n documents. Cross-encoders must process every query-document pair - O(n²). That's why we only use them to re-rank the top K results from the bi-encoder:
def semantic_rerank(query: str, documents: List[str], top_k: int = 50):
# Step 1: Fast bi-encoder gets top candidates (milliseconds)
query_emb = bi_encoder.encode(query)
doc_embs = bi_encoder.encode(documents) # Can be cached!
similarities = cosine_similarity(query_emb, doc_embs)
top_indices = np.argsort(similarities)[-top_k:]
# Step 2: Slow cross-encoder re-ranks just top 50 (seconds)
pairs = [[query, documents[i]] for i in top_indices]
cross_scores = cross_encoder.predict(pairs)
# Step 3: Return re-ranked results
reranked = sorted(zip(top_indices, cross_scores),
key=lambda x: x[1], reverse=True)
return reranked
Usage Examples
Basic Context Building
# Intelligent context extraction
tenets distill "implement OAuth2 authentication"
# With optimizations
tenets distill "implement caching layer" \
--remove-comments \
--condense \
--max-tokens 8000
Sessions with Pinned Files
tenets session create payment-feature
tenets instill --session payment-feature --add-file src/core/payment.py
tenets distill "add refund flow" --session payment-feature
Closing
We're closing in on a future where LLMs are becoming the glue to hold other pieces and services together that fundamentally should be deterministic, even to the point where it can become LLM calls verifying other LLM calls in guardrails that require predictability.
The future of AI pair programming isn't about throwing more compute at the problem or simply relying on models to get bigger and better.
As for the future of tenets, there are clear applications for document similarity matching at the performance and complexity that this library can perform at beyond building developer tools. While tenets is currently fully implemented just to support programming contexts, the modules can easily be packaged out into something composable for any type or genre of documents. At some point I think I'll be using tenets in some capacity for PKMS and other personal bookkeeping.
Install: pip install tenets
Docs: tenets.dev
GitHub: github.com/jddunn/tenets