Intro
Restless is meant to be a suite of security tools with these key features:
- Analysis of files for malware probabilty based on comparing the extracted metadata and file contents with trained Portable Executable data (completed model with around 20 extracted PE header features with ~93% average accuracy in cross-validation training)
- Analysis of system logs for abnormal activities / deviations (not started)
- Constant, efficient and ongoing analysis of system files / logs (in-progress)
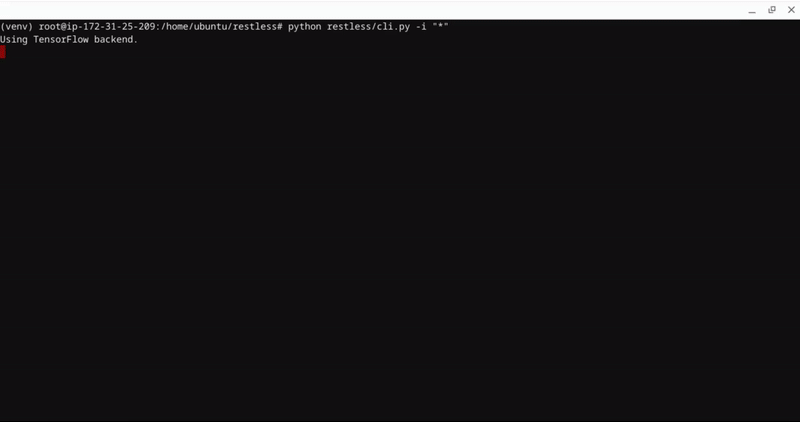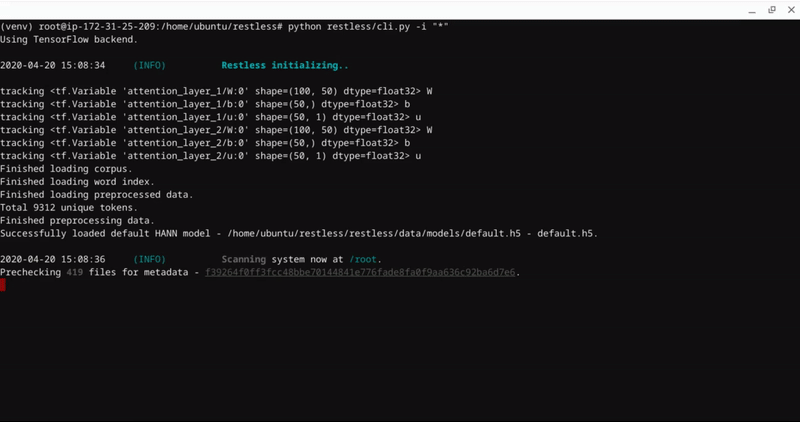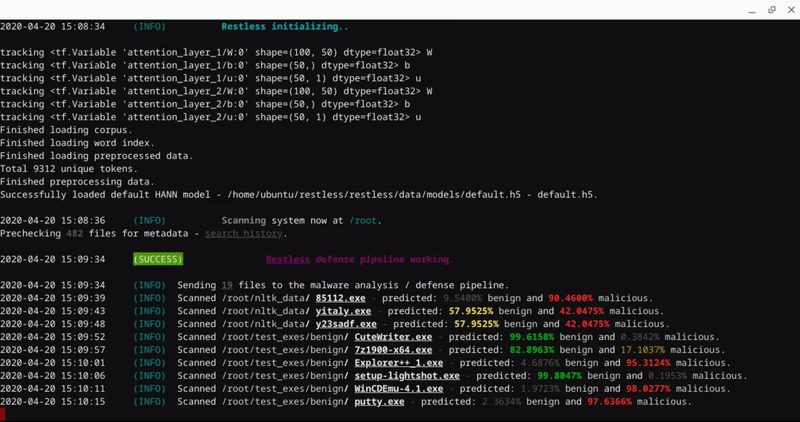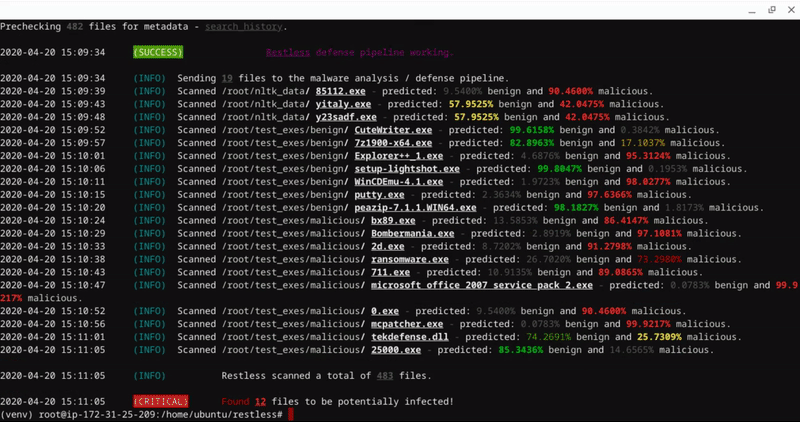 Restless comes with a super sweet CLI.
Restless comes with a super sweet CLI.
Restless aims to be fast and fully functional offline. The current Docker config is for Ubuntu-based machines, but can be modified for other platforms by editing the Dockerfile and docker-compose.yml (eventually, Docker images will be built for Mac and Windows and linked here for download).
Concepts
Signature detection, the traditional method of antiviruses which creates the need to connect to online databases for incessant updating, cannot keep up with the emergence of new malware, or even of known malware that's able to change itself, and while heuristics-based approaches can combat polymorphic viruses while offering further degrees of granularity, they tend to give off so many false positives that they do more harm than good by wasting computing resources and increasing cognitive load.
The incorporation of machine learning (usually, natural language processing techniques although computer vision algorithms can also be applied) in antivirus software empowers them with a level of pattern recognition that previous approaches do not have. Rather than relying on known vulnerabilities / exploits or commonly re-used patterns of malicious code, restless and other ML-powered antiviruses can work well on classifying malware never seen before. This integration of NLP methods with information security has been dubbed malicious language processing by Elastic.
Architecture
Hierarchical attention network (LSTM) for binary classification (benign vs malicious) of EXE files via extracting PE metadata and strings from file contents (including obfuscated strings). The HANN model is perfect as it retains some element of document structure, which is important when analyzing file contents and looking for potentially destructive patterns in code.
HANN trained for system API calls for benign vs malicious binary classification of logs (planned)
K-means clustering for learning unsupervised patterns of abnormal / deviant logs (planned) ..
Restless's current classifications are implemented through a hierarchical attention network, a type of recurrent neural network with an attention layer that can find the most important words and sentences to represent a document, as it is able to read the data in a bidirectional way to learn context.
The architecture from the paper has been modified in Restless's implementation of HAN, in that a vector (array of features) is now acceptable (as well as scalars) for both "sentences" and "words" that build up the vocabulary.
This allows us to represent any arbitrary set of features as a document that the HAN model can learn from, as GloVe (the pre-trained word embeddings) has weights for words as well as numbers. For example, in a word embeddings model like GloVe that considers numbers, a number like 8069 will have contextual meaning (as 8069 would be referenced a lot in computing-related documents).
Typically a document would be tokenized into sentences and then into words to fit the format the HAN model needs, but we can construct a representation of a document that corresponds to the metadata of our file. By extracting PE features like CheckSum, AddressOfEntryPoint, e_minalloc, and more, and considering each feature as a sentence, we can create a HAN classifier that reads executable files and their metadata like documents, and make use of the attention layer so it understands which features have more contextual importance than others.
Originally, Restless's classifier was going to extract strings (including obfuscated strings) from file contents of known malicious and benign files, and then build document representations from that dataset using the hierarchical attention neural network. However, collecting a dataset of executables (from trustworthy sources) is proving to be very time-consuming, so the current focus will focus on the file metadata representation construction.
Research & Results
I did some basic feature selection using Pearson coefficient to see how our features correlate with each other, and since we're doing binary classification, we can get the point-biserial correlation for each feature compared to our target feature (classification of "benign" or "malicious").
Unlike conventional feature selection for regression, our model (HANN) takes a representation of documents as features (features ~= document sentences in this context). For HANN, we care about any feature that has some linear correlation, positive or negative.
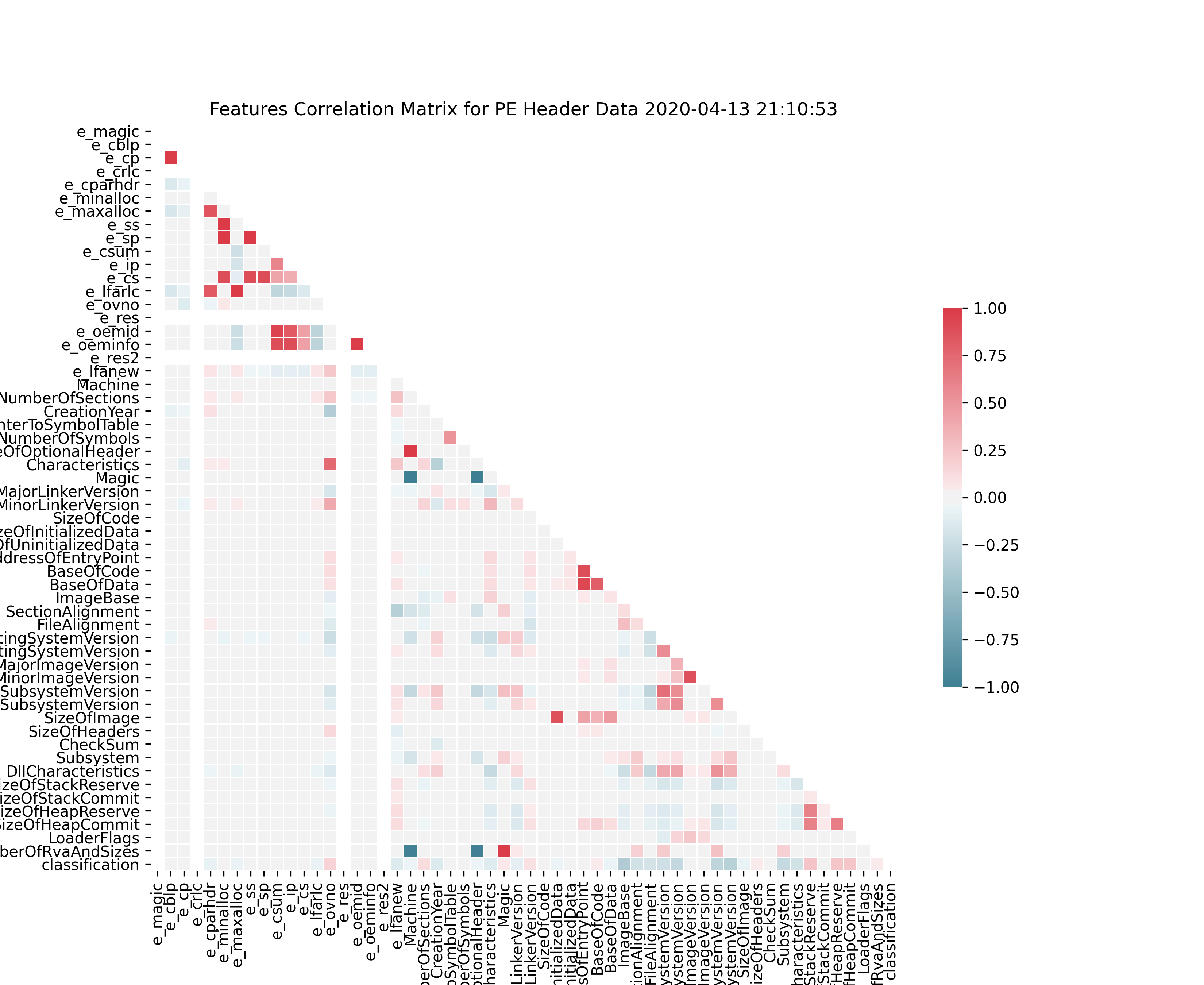 Features Correlation Matrix for PE Header Data.
Features Correlation Matrix for PE Header Data.
.png) Top Features Correlation Matrix for PE Header Data (Minimum threshold of 0.1).
Top Features Correlation Matrix for PE Header Data (Minimum threshold of 0.1).
Training Hierarchical Attention Network Model
(With top extracted PE features correlated with class target, and 5KFold validation)
cd restless/components/nlp/hann
python train_hann.py
Training HANN model now..
Creating HANN model now, with K-Fold cross-validation. K= 1
and length: 4147 1037 for training / validation.
Train on 4147 samples, validate on 1037 samples
Epoch 1/3
- 123s - loss: 0.6237 - accuracy: 0.6173 - val_loss: 0.4314
- val_accuracy: 0.8023
Epoch 2/3
- 121s - loss: 0.3515 - accuracy: 0.8560 - val_loss: 0.3218
- val_accuracy: 0.8804
Epoch 3/3
- 120s - loss: 0.2588 - accuracy: 0.9079 - val_loss: 0.2703
- val_accuracy: 0.8939
..
Metrics summed and averaged: {'accuracy': 0.9328727060163897,
'loss': 2.3185255947187513, 'precision': 0.9461413757441932,
'recall': 0.9280079306100244, 'f1': 0.9356620828481846,
'kappa': 0.8656351205984505, 'auc': 0.9351519030411508}
The best performing model (based on F1 score) was number 3. That
is the model that will be returned.
Training successful.
Saving model to /home/ubuntu/restless/restless/data/models/default.h5.
Stats of our best performing model (highest F1 score):
Model evaluation metrics:
Confusion matrix:
benign malicious
benign 446.0 66.0
malicious 3.0 522.0
None
Accuracy: 0.9334619093539055 Loss: 2.298195125052296
Precision: 0.9942857142857143
Recall: 0.8877551020408163
F1 score: 0.9380053908355795
Cohens kappa score: 0.8666998273038725
ROC AUC score: 0.9405367937821009
Credits
- Malicious executables obtained from http://www.tekdefense.com/downloads/malware-samples/.
- Training dataset taken from https://github.com/urwithajit9/ClaMP.