
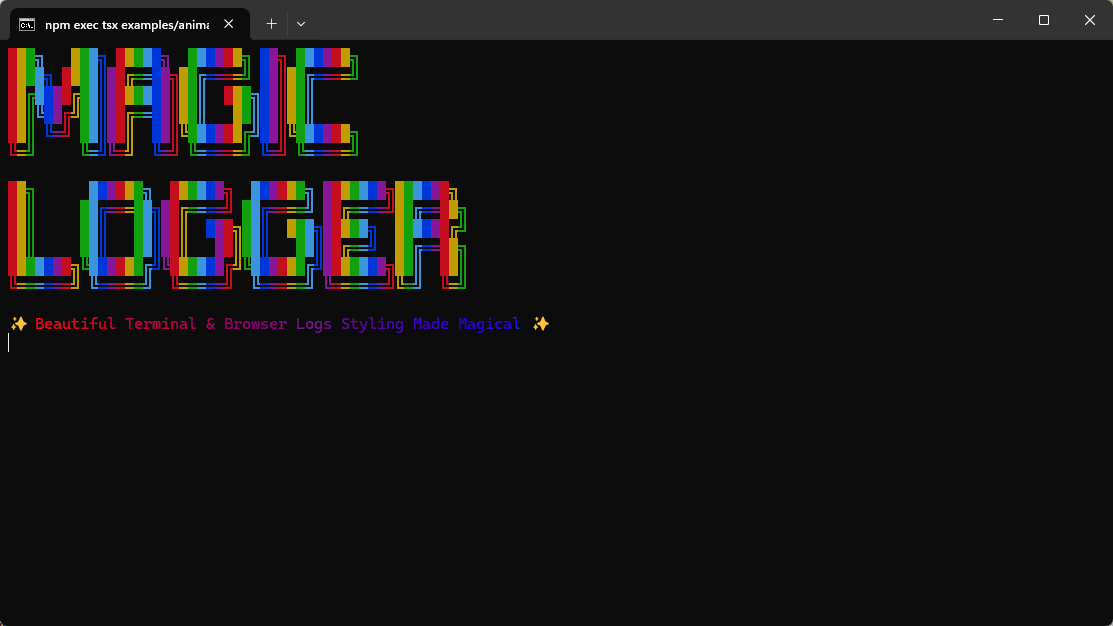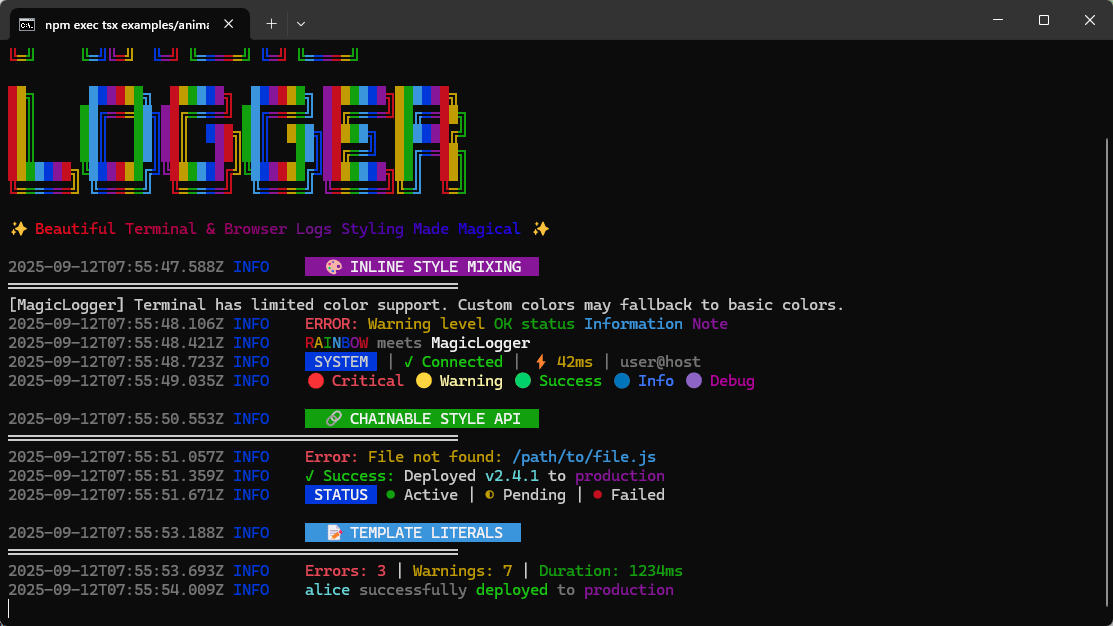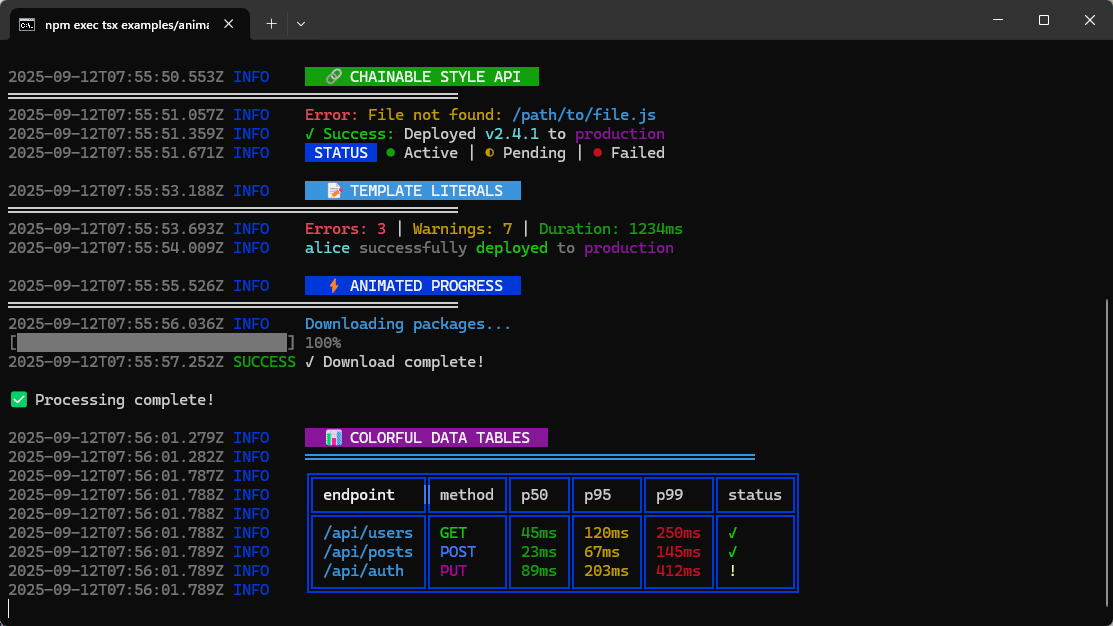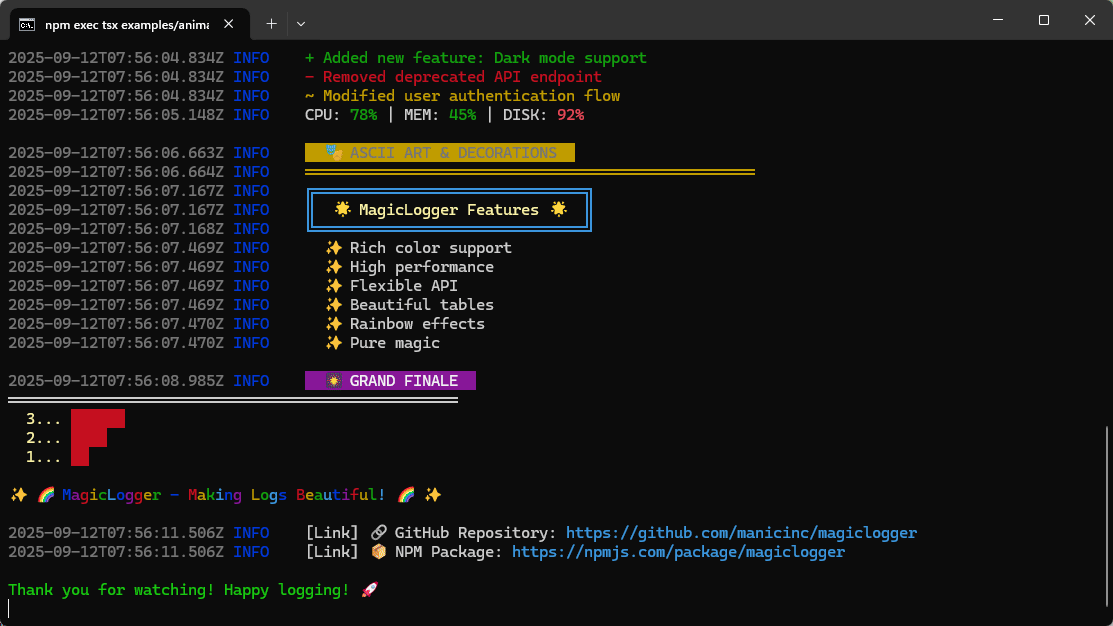
MagicLogger is a library based on an experimental philosophy: what if better-designed logs meant we needed fewer of them?
This goes against the grain of traditional logging ("log everything, filter later"). Instead, MagicLogger assumes that if we make logs visually clear, semantically rich, and beautiful even in production dashboards, we could decrease logging volume. The more context and clarity in each log, the fewer logs we need overall. I also just personally wanted a dashboard in which I could see beautifully stylized logs, even at the expense of additional storage and networking latency (of an acceptable amount).
Strange as it sounds, MagicLogger's niche (that I think it can find) will be for making logs (at least some of them) human-readable.
Using this library generally means you're okay with these assumptions:
- Storage is cheap, some extra kb in many web apps makes little difference
- Some logs sent in production will require human review consistently
- When you analyze logs at a high-level you want a visually appealing experience
MagicLogger achieves 165K ops/sec plain text, 120K+ ops/sec with styled output (faster than bunyan, slower than pino and Winston) while providing full MAGIC schema compliance and OpenTelemetry integration out of the box. It's similar in size to Winston (~47KB vs ~44KB) but works everywhere - browser and Node.js with the same API, and is fully written in TypeScript.
Startups Should Consider Open-Source
Say you're working on putting out a fire, actual $ is on the line, so you shove everything into a commit "fix now" and push direct to prod. Private IP can afford this luxury; open source not so much.
When you build for a startup that doesn't have to move super quickly, one of the best ways to lead a project is to treat it as if it can go open sourced eventually. From the 2023 State of Open Source Report, 90% of IT leaders are using enterprise open source solutions.
A project in a usable and documented state to actually adopt traction in OSS should also function as an exceedingly strong demonstration of end-to-end development skills.
Can we get some color in our logs?
I have been remaking high-level loggers for years. Industry standard libraries for JS, like winston are powerful but don't have the most straightforward APIs. Pino is great, lightweight and fast, but simple by design and Node.js only.
Here's how different libraries handle colors in the JS ecosystem:
Winston requires multiple packages and complex configuration:
import winston from 'winston';
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.colorize(), // This only works for console
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) =>
`${timestamp} [${level}]: ${message}`)
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'app.log' }) // No colors here!
]
});
// Want to style part of a message? You need chalk
import chalk from 'chalk';
logger.info(`User ${chalk.cyan('john@example.com')} logged in`);
// File output: "User john@example.com logged in" (no color info preserved)
Pino deliberately excludes colors from production:
import pino from 'pino';
// Basic pino - NO COLORS AT ALL
const logger = pino();
logger.info('Server started'); // {"level":30,"time":1234567890,"msg":"Server started"}
// Want colors? Need pino-pretty (200KB extra!)
// Even with pino-pretty, you can't style parts of messages
// Want colors in production? Against pino's philosophy
// Want to use in browser? Not supported
Now MagicLogger's styling:
// MAGICLOGGER (preserves everything, works everywhere)
import { Logger } from 'magiclogger';
const logger = new Logger();
logger.error('<red.bold>CRITICAL:</> Database <yellow>MongoDB</> unreachable');
// Console: Beautifully styled
// File: {"message": "CRITICAL: Database MongoDB unreachable",
// "styles": [[0, 9, "red.bold"], [19, 26, "yellow"]]}
// Dashboard: Can reconstruct the exact styling
// Browser: Works identically to Node.js
MagicLogger isn't just adding colors - it's preserving the semantic meaning of those colors throughout your entire logging pipeline.
MAGIC Schema - Complete Observability by Default
The MAGIC schema (MagicLog Agnostic Generic Interface for Consistency), an open format for structured log entries that enables seamless integration and recreation of logging styles. Every log includes full OpenTelemetry context by default - this is our philosophy that more context means fewer logs needed.
{
"timestamp": "2024-01-15T10:30:45.123Z",
"level": "info",
"message": "Server started on port 3000",
"styles": [[0, 14, "green.bold"], [23, 27, "yellow"]],
"context": {
"service": "api-gateway",
"version": "2.1.0"
},
"trace": {
"traceId": "4bf92f3577b34da6a3ce929d0e0e4736", // Always included
"spanId": "00f067aa0ba902b7" // Always included
},
"metadata": {
"hostname": "api-server-01",
"pid": 12345
}
}
This complete observability approach means you can correlate any log with distributed traces, understand the full context, and need fewer logs to debug issues.
Making Things Fast
Style Extraction in Linear Time
Style extraction from our angle-bracket templating syntax efficiently is done in one-pass in linear time and memory:
export function extractStyles(message: string): ExtractedStyles {
// Fast path for plain text
if (!message.includes('<')) {
return { plainText: message, styles: [] };
}
// Array accumulation is more efficient than string concatenation
// JavaScript strings are immutable, causing O(n²) complexity with +=
// Using array + join() gives us O(n) complexity
const plainParts: string[] = [];
const styleRanges: StyleRange[] = [];
let plainTextPos = 0; // Position in output (without tags)
// Regex: <([^>]+)> prevents backtracking, ([^<]*) deterministic matching
const regex = /<([^>]+)>([^<]*)<\/>/g;
let lastIndex = 0;
let match;
// Main extraction loop - O(n) complexity
while ((match = regex.exec(message)) !== null) {
// Phase 1: Capture unstyled text before match
if (match.index > lastIndex) {
const plainText = message.slice(lastIndex, match.index);
plainParts.push(plainText);
plainTextPos += plainText.length;
}
// Phase 2: Process styled content
const styles = match[1].split('.'); // "red.bold" → ["red", "bold"]
const content = match[2];
if (content) {
styleRanges.push({
start: plainTextPos,
end: plainTextPos + content.length,
styles
});
plainParts.push(content);
plainTextPos += content.length;
}
lastIndex = regex.lastIndex;
}
return {
plainText: plainParts.join(''),
styles: styleRanges
};
}
Our logger also keeps styles in a LRU cache, making the assumption that oftentimes styles will be reused and shouldn't be recalculated.
const styleCache = new LRUCache<string, ExtractedStyles>(10000);
const cached = styleCache.get(message);
if (cached) return cached;
Performance Comparison
| Logger | Architecture | Plain Text | Styled | Bundle | Works In |
|---|---|---|---|---|---|
| Pino | Async I/O, Node-only | 560K ops/sec | N/A | 25KB | Node.js only |
| Winston | Multi-stream | 307K ops/sec | 446K ops/sec | 44KB | Node.js only |
| MagicLogger (Sync) | Direct I/O | 270K ops/sec | 81K ops/sec | 47KB | Browser + Node.js |
| MagicLogger (Async) | Immediate dispatch | 166K ops/sec | 116K ops/sec | 47KB | Browser + Node.js |
| Bunyan | JSON, Node-only | 85K ops/sec | 99K ops/sec | 30KB | Node.js only |
Key insights:
- MagicLogger is the only production logger that works in both browsers and Node.js
- Async styled (116K ops/sec) has only 11.8% overhead thanks to optimized caching
- Performance trade-off is intentional: complete observability over raw throughput
CI/CD: Actions and Abstractions
I was foolhardy with GitHub actions. Giddy with excitement, I had my ci.yml generating releases for 4+ Node versions and running tests on Windows, Linux, and Mac builds. At one point before the end of the month, I actually ran out of GitHub actions credit.

I had auto-pr-summary.yml summarizing PRs by aggregating commits, auto-label.yml adding labels based on filepaths, release-drafter.yml and release.yml drafting and publishing releases.

Testing & Documentation
We have ~75% test coverage (enforced at 70%) with over 2000 tests. Testing was by far the most time-consuming part, but necessary. Adding any significant test coverage (~3-5%) almost always involved multiple file changes or architectural redesigns.
As a comparison, winston is at 69% code coverage. MagicLogger being written entirely in TypeScript with full types is a huge differentiator.

AI Coding Can Be Exponential in Both Development and Failure
MagicLogger was worked on for about 9 months on-and-off part-time. AI, both Claude and GPT-4 family, made the development speed possible. What people rarely talk about with AI pair programming is how great failure and losses can be.
Here's a paraphrased actual interaction:
Claude: "For better performance, you should implement batching optimization directly in the AsyncLogger with a centralized manager that processes all logs before sending to transports…"
It does sound reasonable (especially coming from an authoritative tone) but architecturally is obviously wrong if you just take the next step in the logical process. Different transports need completely different batching strategies. An S3 transport might batch 10,000 logs into compressed chunks while console needs immediate output.

After alerting Claude to its mistake, it instantly self-corrected, though we know at the mere suggestion the LLM will bias its answer.
Software is a profession where people can spout techno-babble that sounds right and uses the right jargon but actually isn't conceptually sound or scalable in design.
Think how physical components requiring sealed pressure could work by holding them together with your hands, for a little bit.
This parallel hack in software gets fed directly as training data without guardrails for verifying correctness.
Sourcery AI Code Reviews

Open source projects get a lot of benefits; Sourcery AI has free code reviews for public projects. Sourcery can provide comprehensive in-depth analysis revealing patterns, design decisions, and potential warnings that oftentimes get forgotten especially when managing 3+ PRs.
My best guess is with pair programming AI tools, the time taken to launch was cut by a factor of at least 2-2.5x.
Usage Examples
Basic Setup
import { Logger } from 'magiclogger';
const logger = new Logger();
// Simple, intuitive styling syntax
logger.info('<green.bold>Server started</> on port <yellow>3000</>');
logger.error('<red>Database connection failed:</> <dim>{error}</>', { error });
// Automatic theming with tags
logger.tag(['api', 'auth']).info('User authenticated');
Advanced Configuration
const logger = new Logger({
async: true, // High throughput mode
transport: [
new ConsoleTransport({ colors: true }),
new FileTransport({ path: 'app.log' }),
new HttpTransport({ endpoint: 'https://logs.example.com' })
],
extensions: [
new RateLimiter({ maxPerSecond: 1000 }),
new Redactor({ patterns: [/password/gi] }),
new Sampler({ rate: 0.1 }) // Sample 10% in production
],
theme: 'cyberpunk'
});
// With context and tags
logger
.context({ requestId: '123', userId: 'abc' })
.tag(['api', 'critical'])
.error('Database connection failed');
The future of logging might not be about processing more logs faster or storing more of them, but allowing them to be so informative that we simply need fewer.
Try it: npm install magiclogger
Docs: magiclog.io
GitHub: github.com/manicinc/magiclogger