Intro
Emote / Emoter / A Poor Sort of Memory were all created during my undergraduate thesis at Parsons School of Design. I deployed Emoter in an anachronistic, interactive exhibit (seen below) at the Parson's 2017 BFA thesis show, with a personality that represents myself, created from parsing my archived messages on Facebook.
While the code and dataset was open-source while I was in school, the IP for Emote and Emoter was sold to the startup HAL, and so is no longer open-source.
I had originally wanted to create a wearable product integrated with a talking AI, and while looking at all the existing chatbot solutions, I felt dissatisfied. I felt that chatbots should have some way to comprehend messages for some higher meaning, as an actual human mind would. Naturally, empathy seemed like a great way to answer for that higher meaning.
A chatbot with emotional intelligence could not only be able to narrow down schemas in its knowledge database to give more specific, accurate answers, but the bot could also then decipher and understand the emotional context of texts that aren't similar to anything in its training.
I looked to integrate a sentiment analyzer with my bot. I tried a few solutions, and again, felt dissatisfied with them all, including Watson's Tone Analyzer (which, as the name states, is for analyzing the tone of how text comes off, not actually how the person is feeling). Again, I began creating my own, with the help of several open-source libraries.
Emote: Sentiment analysis library
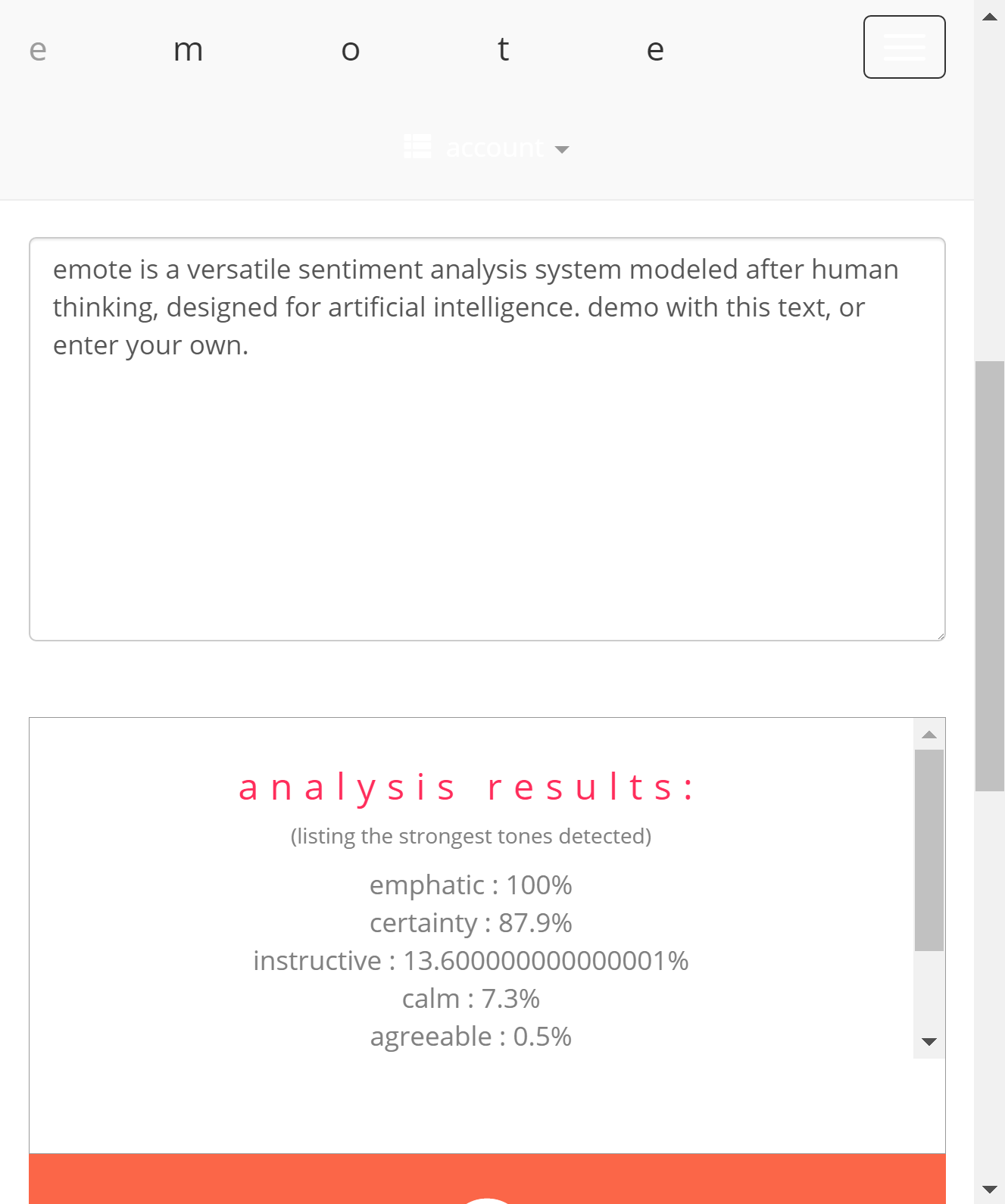
Emote was written in Python and uses the TextBlob / NLTK, NumPy, pandas, and scikit-learn libraries to build a probabilistic sentiment analyzer for 26 different classifications. These classifications have been divided into 13 pairs of opposites, and are designed to be grouped together to create tone clusters that can then encompass more values as well as decrease false positives.
Based off these tone clusters, a further 10 additional tone classifications are derived, allowing for 36 different tones to be detected.
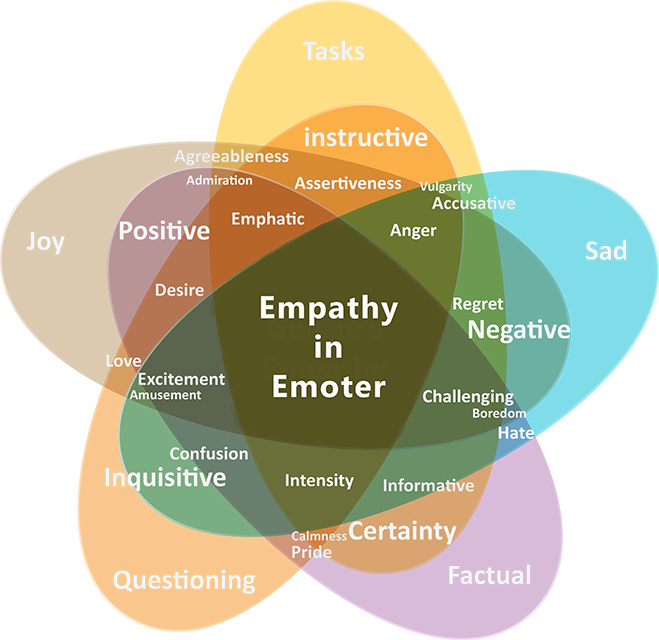 How the emotional tones were clustered and classified in Emote.
How the emotional tones were clustered and classified in Emote.
I developed the training data for this by classifying ~10,000 quotes of dialog and text from literature and film texts. It was fed into a Naive Bayes classifier. I also developed an algorithm to parse 70,000 of my Facebook messages, in order to "clone" a digital replica of myself that would respond with messages I have said before. It also was integrated with Emote's sentiment analysis, to judge the emotions behind a user's message and respond accordingly with appropriate emotional tones.
A Naive Bayes classifier was chosen for a few reasons, mainly because of the feature-independent probability classification.
Naive Bayes starts with an initial guess based on what it's seen before; it will guess more common classifications more often. This made sense as I had classifications like "positive", "negative", as well as "joyful", or "anger", and the more generalized tones like positive / negative had a greater frequency of labels, and thus were classified more often.
To combat the limitation of potentially only getting classified by the most frequent tones in the training set, I took the highest 3-6 emotional tone probabilities, and normalized them to become more like percentages by reducing the variance between the class values, assuming that if a tone was in the top 5-6 classes found, there was some decent percentage of that tone detected in the text.
To achieve that normalization, I first used the StandardScaler class from scikit-learn's preprocessing methods (which worked effectively despite that it's usually meant for data preprocessing, not normalizing data outputs). I was planning to then apply the softmax function to transform those values back into a probability distribution that added up to 1, which exponentiates the probabilities and then divides them by the sum of all exponentiated scores, which would result in even further reduced variance. However, I decided not to, as I didn't want to limit the tones to add up to a 100% percentage, but instead be able to co-exist as a 100% value alongside other tones with percentages, since my detection was meant to analyze multiple tones simultaneously.
Once I had the values from the Standard Scaler transformation, I multiplied them by 100 to achieve a percentage. The Robust Scaler transformation from the same library would be more effective for normalizing outliers, but my class imbalances were not so great that it was needed in my opinion, and by design was supposed to be somewhat imbalanced for more niche tones versus more general ones.
Because I only had ~10k examples in my dataset, the feature independence of the Naive Bayes model worked well, as it simplifies the complexity and thus the amount of data needed to estimate probabilities, while still retaining a high amount of dimensions.
Each n-gram is considered a separate feature in the training, so I had to choose between unigrams, bigrams, trigrams, or further n-grams. Since my dataset was limited, I went with unigrams, despite the fact that no context beyond each word was considered, as the classifier would still take into account the frequency of every word (or n-gram) in the text. For me, the tradeoff for higher accuracy in a smaller dataset was worth the classifier risking inaccuracies when analyzing phrases like "that was so not good", versus "not! that was so good", which I figured would often be fringe cases.
In the future, a Naive Bayes model based on bigrams or even trigrams with a 100k examples in the training dataset would be more versatile and presumably more accurate than this model.
Emote image gallery
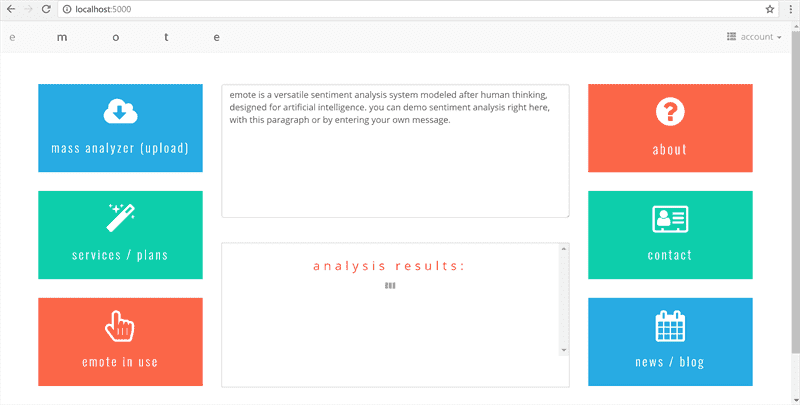 Emote has a web interface built in Flask and with Bootstrap.
Emote has a web interface built in Flask and with Bootstrap.
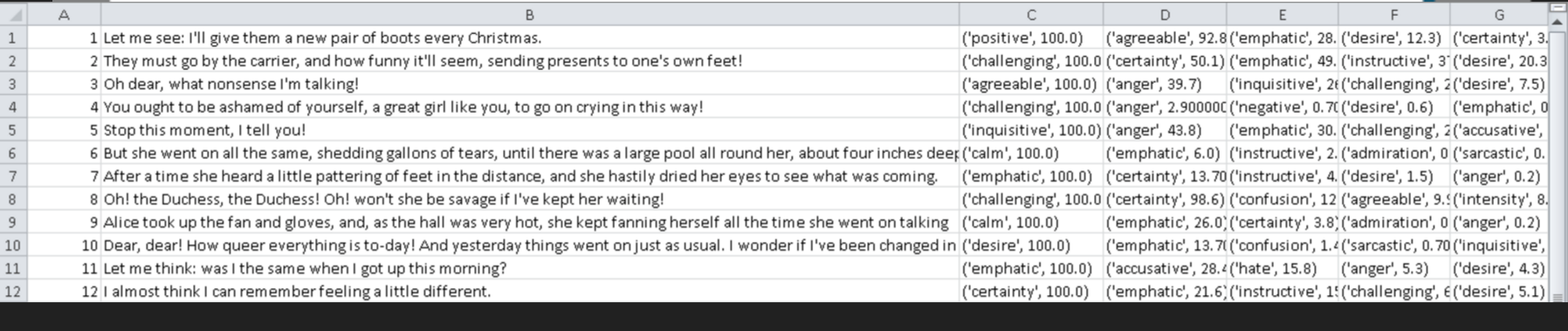 Emote has a mass analysis feature for analyzing CSV or text files, including PDFs / books.
Emote has a mass analysis feature for analyzing CSV or text files, including PDFs / books.
Emoter: Chatbots with empathy and memory
Emoter is a basic but functional chatbot platform intergrated with Emote (also in Python), in order to give chatbot agents the ability to empathize with users and give back emotionally appropriate responses.
Emoter agents thus can operate on a "higher level of thinking", by first categorizing messages and then choosing specific, interchangeable "conversations" (lists of text responses) to respond from based on certain emotional tones.
Within these conversations, Emoter looks for matching text in its database and compares it with the user input on a sliding threshold, outputting the corresponding response if the threshold is met. This "message-response" pair matching algorithm was simple (by design, as the NLP for matching responses in a conversation was not the focal point of hte project): It used cosine similarity after extracting the most important text words after some tf-idf (term frequency - inverse document frequency) analysis, which measures the importance of a word by weighing how often it appears in a single document then offsetting that by the frequency of the word's appearance in the entire corpus.
The combined approach of cosine similarity and tf-idf filtering worked well, as the similarity threshold required for matching an appropriate response was much lower than if it checked for the entire text without filtering, so often multiple appropriate responses were matched even with a relatively small dataset, and the response chosen was randomized from the appropriate ones found, allowing for a dynamic conversation experience.
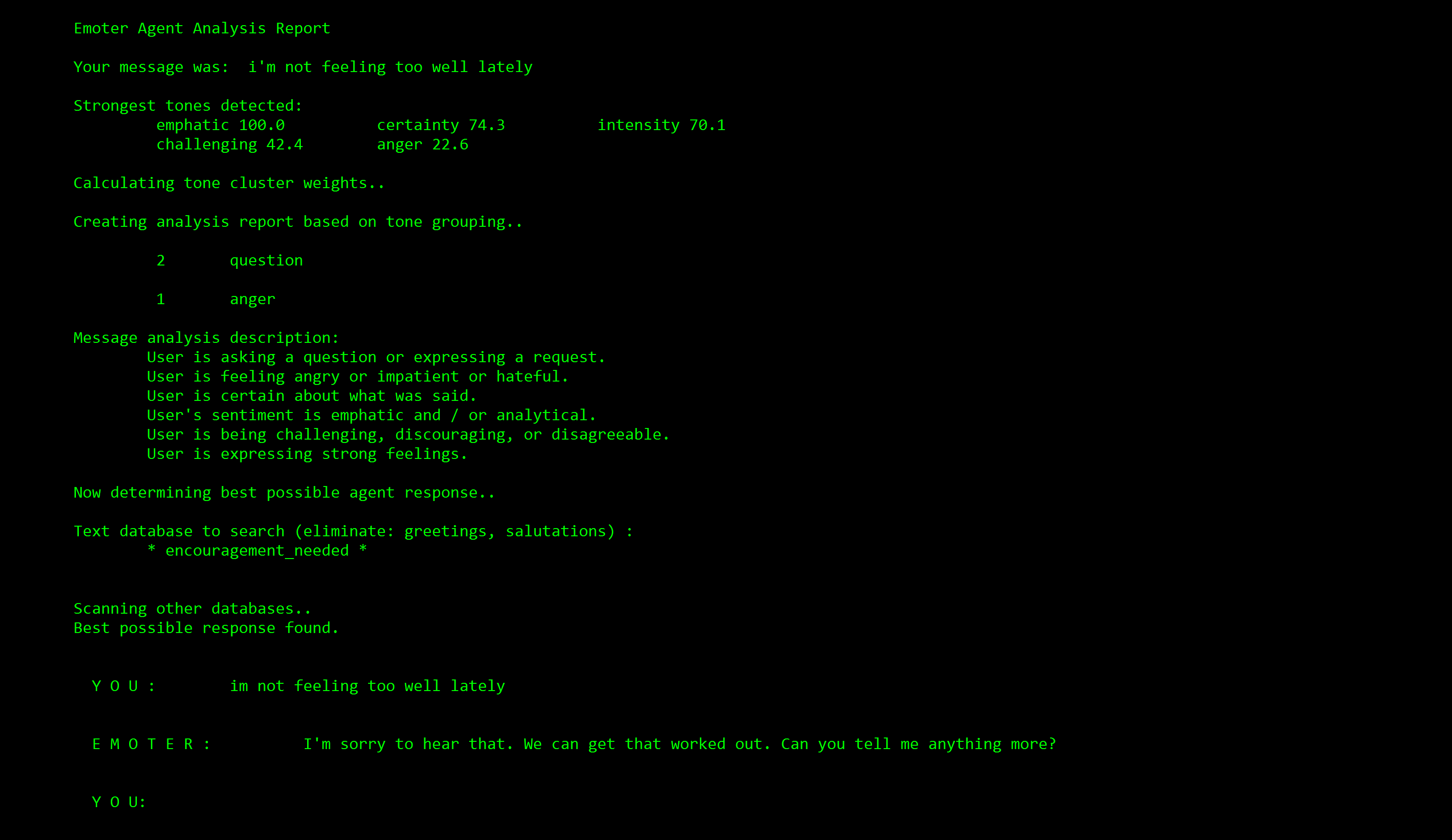 A demo 'Emoter agent' with a persona of a fitness coach.
A demo 'Emoter agent' with a persona of a fitness coach.
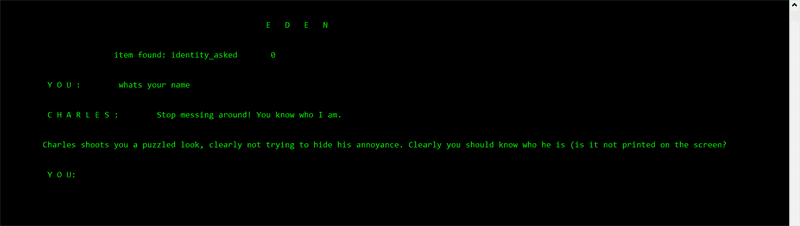
In Emoter's training data, values can be passed into the list of lists (2D array) after any input-response pair, and checked for before Emoter gives out a response. In my interactive fiction game demo Eden, I used this to create a branching narrative driven by the mechanic of talking to the only other interactable character.
The Emoter bot was able to keep track of whether or not certain things were said by the user previously, and how often each thing was said. Thus, Emoter bots can be written with limited short-term "memory" features, so that they can continue speaking on the same conversations.
A poor sort of memory, or, how to build a digital replica of yourself with empathy
Finally, while developing Emoter, I became more fascinated with the idea of automatically generating digital personalities of individual people, specifically given their archived data on social media (inspired by Black Mirror's episode Be Right Back. I developed an algorithm to parse 70,000 of my Facebook messages (downloaded from their official service), to create a database Emoter could use that was specifically mined from my words. This project was deployed as an interactive exhibit in a gallery.
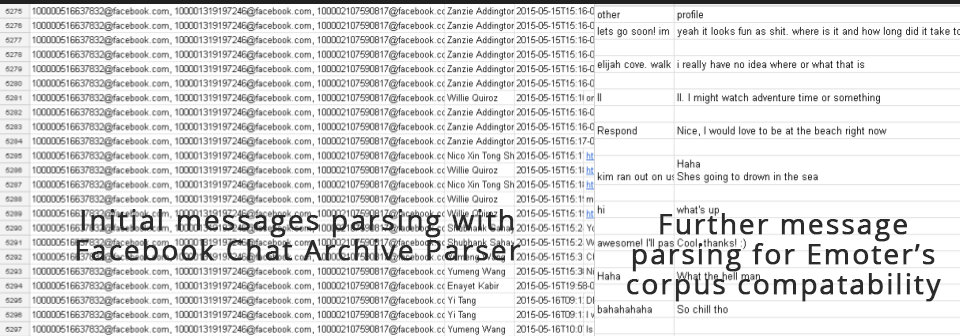 Facebook message records transformed into message-pair responses for the chatbot using a parsing algorithm.
Facebook message records transformed into message-pair responses for the chatbot using a parsing algorithm.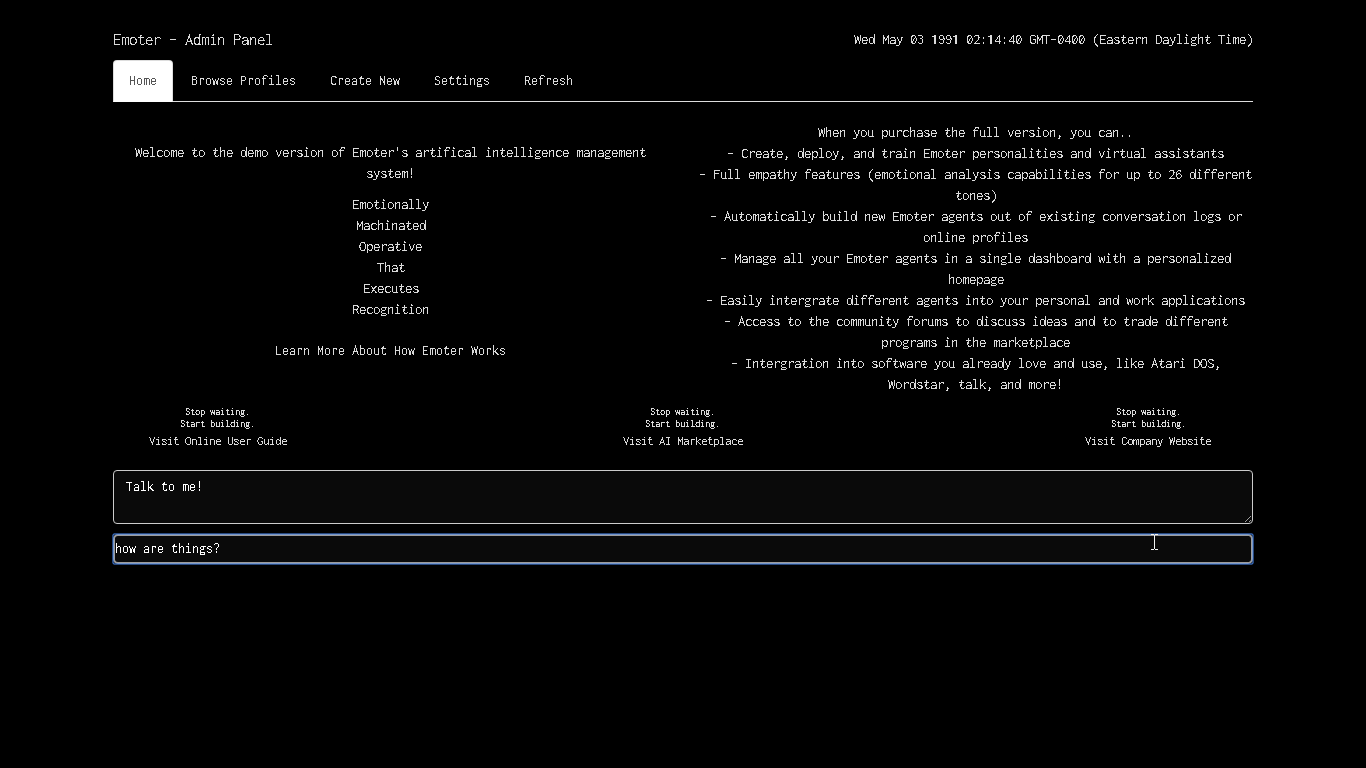
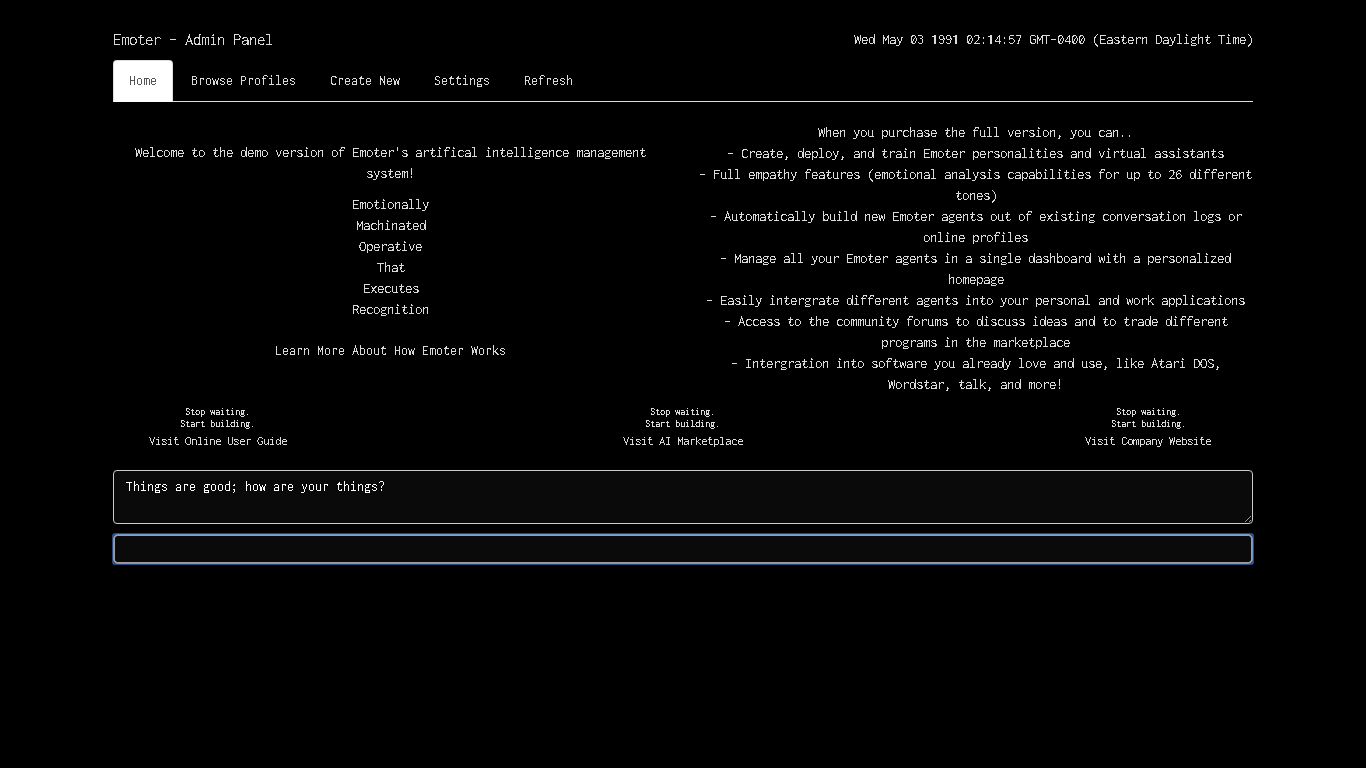
 A poor sort of memory that only works backwards.
A poor sort of memory that only works backwards.
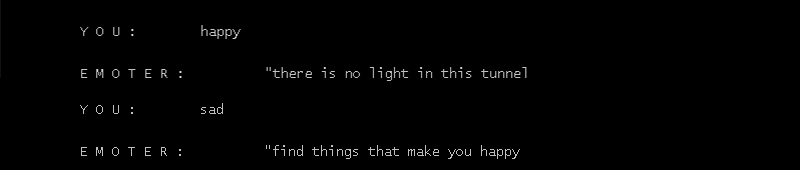
Users talking to the chatbot during the gallery, and the chatbot demonstrating emotional understanding of the message intents and responding accordingly (logs saved from the backend):